Python爬虫破解有道翻译
上一节《浏览器实现抓包过程详解》,通过控制台抓包,我们得知了 POST 请求的参数以及相应的参数值,如下所示:
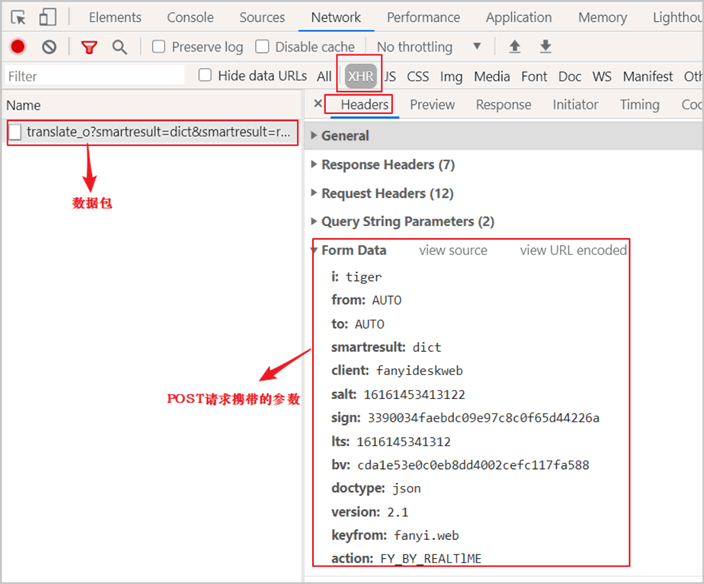
图1:有道翻译POST请求参数
并发现以下了规律:salt、sign、lts 总是变化的,而 bv 等其他参数是不变化的。其中 lts 代表毫秒时间戳,salt 和 lts 之间存在着某种关联,因为两者只有一个数字是不同的;而 sign 对应的值是一个加密后的字符串。
如果想要实现实时地抓取翻译结果,就需要将 salt 和 sign 转换为 用 Python 代码表示的固定形式。将所有参数放入到 requests.post() 中,如下所示:
其中 data 是字典格式参数,它用来构建 POST 请求方法的参数和参数值。response = requests.post(url,data=data,headers=headers)
JS代码slat与sign
salt、sign 加密有两种实现方式:一种是通过前端 JS 实现,另一种是后台服务器生成加密串,并在返回响应信息时,将加密信息交给接浏览器客户端。但是,通过预览响应信息可知,并没有涉及 salt、sign 的信息,因此可以排除这种方法。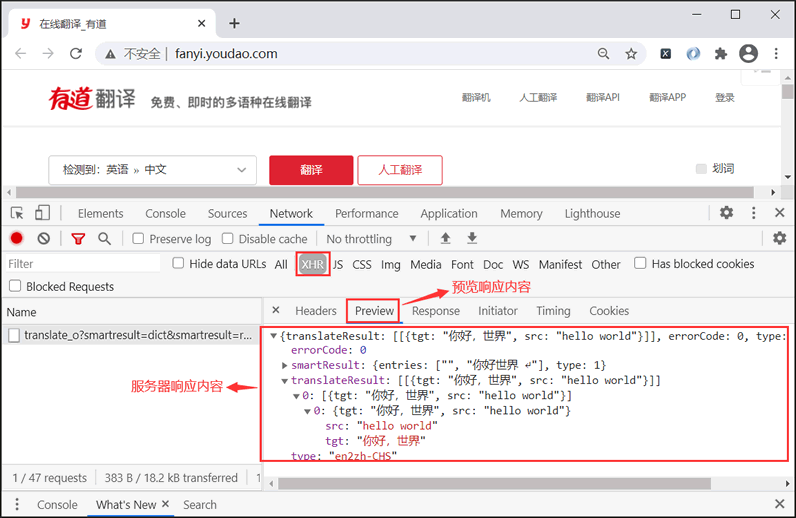
图2:预览响应信息
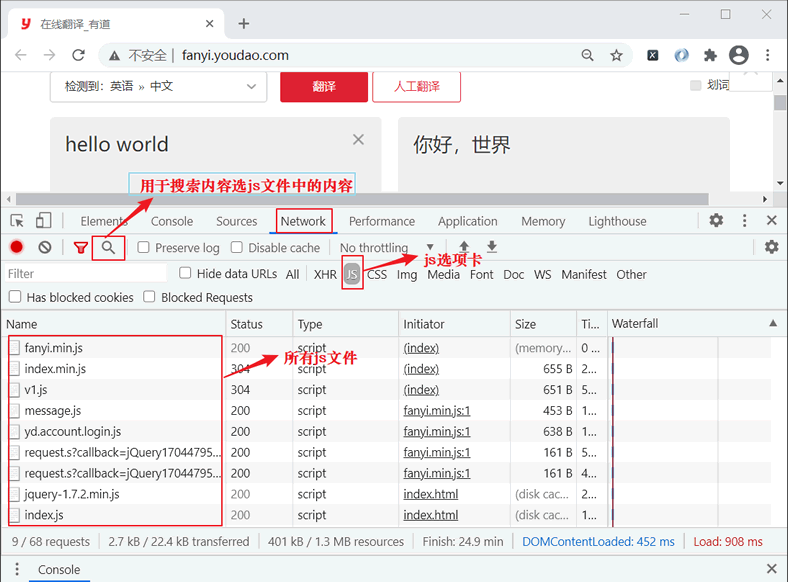
图3:js文件
点击上图所示的搜索按钮来检索 JS 代码,输入 "salt",结果如图所示:
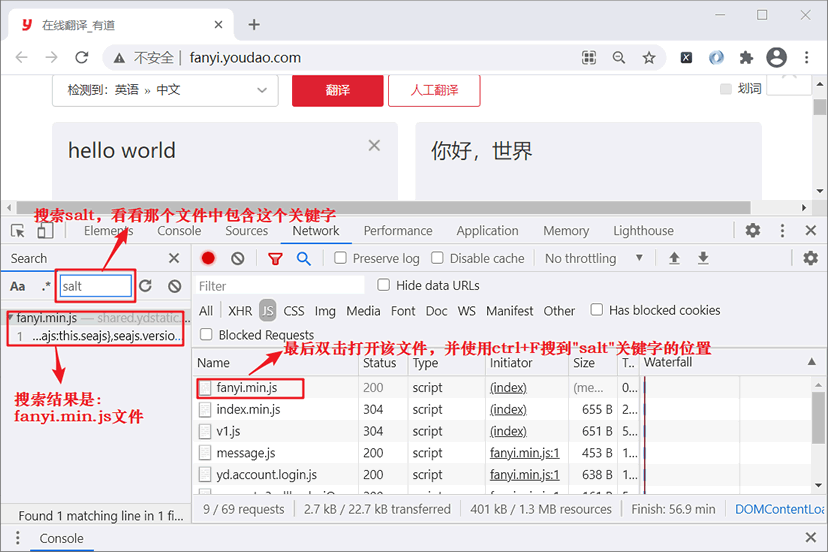
图4:找到相关js文件
或者您也可以使用 Sources 选项卡将 fanyi.min.js 文件中的 JS 代码格式化输出,并使用 Ctrl+F 找到相应的 "salt" 位置,如下图所示:
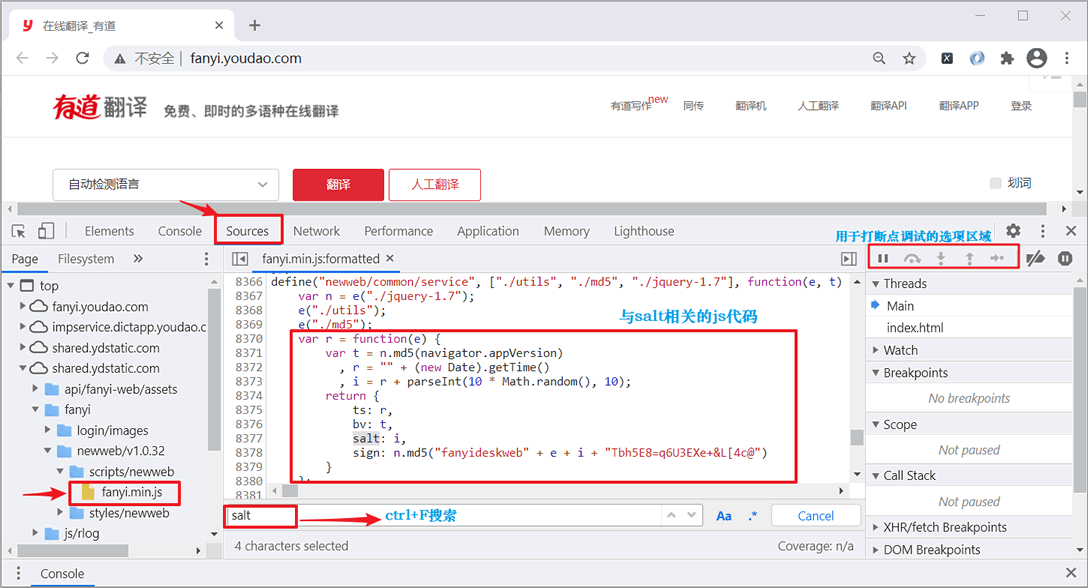
图5:Sources选项卡应用
提示:将所有 JS 代码 copy 下来,通过站长工具也可以实现格式化输出。
通过上述方法就找到了 salt 与 sign(两个参数项是在一起的)JS 代码,如下所示:
var r = function(e) {
var t = n.md5(navigator.appVersion),
r = "" + (new Date).getTime(),
i = r + parseInt(10 * Math.random(), 10);
return {
ts: r,
bv: t,
salt: i,
sign: n.md5("fanyideskweb" + e + i + "Tbh5E8=q6U3EXe+&L[4c@")
}
};
注意,找到上述代码是解决本节问题的关键,大家一定要要掌握方法。
Python代码表示参数
通过上述 JS 代码的简单分析可知: r 变量等同于 lts,salt 变量等同于 i,而 sign 是一个经过 md5 加密的字符串。接下来使用 Python 代码来表示上述参数,如下所示:#lts毫秒时间戳
str(int(time.time()*1000))
#salt, lts+从0-9的随机数
lts+str(random.randint(0,9))
#sign加密字符串
from hashlib import md5
#word为要翻译的单词等同于js代码中的"e"
string = "fanyideskweb" + word + salt + "Tbh5E8=q6U3EXe+&L[4c@"
s = md5()
#md5的加密串必须为字节码
s.update(string.encode())
#16进制加密
sign = s.hexdigest()
完整程序实现
完整代码如下所示:
#coding:utf8
import random
import time
from hashlib import md5
import requests
class YoudaoSpider(object):
def __init__(self):
# url一定要写抓包时抓到的POST请求的提交地址,但是还需要去掉 url中的“_o”,
# “_o”这是一种url反爬策略,做了页面跳转,若直接访问会返回{"errorCode":50}
self.url='http://fanyi.youd网站站点" rel="nofollow" />
请输入要翻译的单词:大家好,这里是C语言中文网Python爬虫教程
lts,salt,sign 输出结果:
16164720920902 fcc592626aee42e1067c5195cf4c4576
html 响应内容:
{'type': 'ZH_CN2EN', 'errorCode': 0, 'elapsedTime': 25, 'translateResult': [[{'src': '大家好,这里是C语言中文网Python爬虫教程', 'tgt': 'Everybody is good, here is the Chinese Python crawler C language tutorial'}]]}
翻译结果: Everybody is good, here is the Chinese Python crawler C language tutorial
- 随机文章
- 核心危机(核心危机魔石合成攻略)
- 风儿(风儿轻轻的吹)
- 饿了么红包怎么用(饿了么红包怎么用微信支付)
- 儿童教育文章(儿童教育)
- 光遇花手先祖位置(安卓光遇手花先祖)
- 广州4a广告公司(广州4a广告公司创意总监年薪)
- 抖音卡(抖音卡顿怎么解决)
- xboxones(xboxone手柄怎么配对主机)
- 兵马俑(兵马俑介绍和历史背景)
- 陈武简历
- 帆船比赛(帆船比赛视频)
- 海猫鸣泣之时游戏(海猫鸣泣之时游戏在哪玩)
- 韩国媳妇和小雪(韩国媳妇和小雪的父亲工资是多少)
- 儋州市第二中学(儋州市第二中学录取分数线)
- 鬼泣5攻略(鬼泣5攻略第三关怎么跳)
- 和柳亚子(和柳亚子先生于田)
- 冰客(冰客果汁)
- yy魔兽(yy魔兽世界)
- 充值卡代理(充值卡代理加盟)
- 拆奶罩
- 郭妮小说(恶魔的法则郭妮小说)
- 东天目山(东天目山景区)
- 杭同(杭同培训中心怎么样)
- 蝙蝠给人类的一封信(蝙蝠给人类的一封信)
- 大松电饭煲(美的大松电饭煲)
- 疯狂填字(疯狂填字5)
- 点对点短信息(点对点短信息费是什么意思)
- 观音普门品(观音普门品念诵全文)
- 河北省大运会(河北省大运会时间)
- 杜星霖(杜星霖图片)