网页是怎样构成的
爬虫程序之所以可以抓取数据,是因为爬虫能够对网页进行分析,并在网页中提取出想要的数据。在学习 Python 爬虫模块前,我们有必要先熟悉网页的基本结构,这是编写爬虫程序的必备知识。
如果您熟悉前端语言,那么您可以轻松地掌握本节知识。
网页一般由三部分组成,分别是 HTML(超文本标记语言)、CSS(层叠样式表)和 JavaScript(简称“JS”动态脚本语言),它们三者在网页中分别承担着不同的任务。
HTML 负责定义网页的内容
CSS 负责描述网页的布局
JavaScript 负责网页的行为
HTML
HTML 是网页的基本结构,它相当于人体的骨骼结构。网页中同时带有“<”、“>”符号的都属于 HTML 标签。常见的 HTML 标签如下所示:
<!DOCTYPE html> 声明为 HTML5 文档
<html>..</html> 是网页的根元素
<head>..</head> 元素包含了文档的元(meta)数据,如 <meta charset="utf-8"> 定义网页编码格式为 utf-8。
<title>..<title> 元素描述了文档的标题
<body>..</body> 表示用户可见的内容
<div>..</div> 表示框架
<p>..</p> 表示段落
<ul>..</ul> 定义无序列表
<ol>..</ol>定义有序列表
<li>..</li>表示列表项
<img src="" alt="">表示图片
<h1>..</h1>表示标题
<a href="">..</a>表示超链接
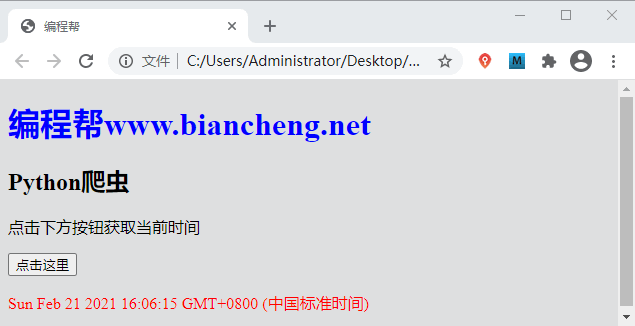
编写如下代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>编程帮</title>
</head>
<body>
<a href="www.biancheng网站站点" rel="nofollow" />
图1:HTML网页结构
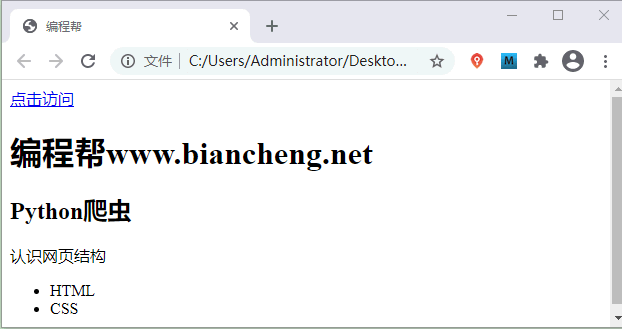
CSS
CSS 表示层叠样式表,其编写方法有三种,分别是行内样式、内嵌样式和外联样式。CSS 代码演示如下:
<!DOCTYPE html>
<html>
<head>
<!-- 内嵌样式 -->
<style type="text/css">
body{
background-color:yellow;
}
p{
font-size: 30px;
color: springgreen;
}
</style>
<meta charset="utf-8">
<title>编程帮</title>
</head>
<body>
<!-- h1标签使用了行内样式 -->
<h1 style="color: blue;">编程帮www.biancheng网站站点" rel="nofollow" />
图2:CSS样式表演示