Python多线程爬虫详解
网络爬虫程序是一种 IO 密集型程序,程序中涉及了很多网络 IO 以及本地磁盘 IO 操作,这些都会消耗大量的时间,从而降低程序的执行效率,而 Python 提供的多线程能够在一定程度上 IO 密集型程序的执行效率。
如果想学习 Python 多进程、多线程以及 Python GIL 全局解释器锁的相关知识,可参考《Python并发编程教程》。
多线程使用流程
Python 提供了两个支持多线程的模块,分别是 _thread 和 threading。其中 _thread 模块偏底层,它相比于 threading 模块功能有限,因此大家使用 threading 模块。 threading 中不仅包含了 _thread 模块中的所有方法,还提供了一些其他方法,如下所示:
threading.currentThread() 返回当前的线程变量。
threading.enumerate() 返回一个所有正在运行的线程的列表。
threading.activeCount() 返回正在运行的线程数量。
线程的具体使用方法如下所示:
from threading import Thread
#线程创建、启动、回收
t = Thread(target=函数名) # 创建线程对象
t.start() # 创建并启动线程
t.join() # 阻塞等待回收线程
创建多线程的具体流程:
除了使用该模块外,您也可以使用 Thread 线程类来创建多线程。t_list = []
for i in range(5):
t = Thread(target=函数名)
t_list.append(t)
t.start()
for t in t_list:
t.join()
在处理线程的过程中要时刻注意线程的同步问题,即多个线程不能操作同一个数据,否则会造成数据的不确定性。通过 threading 模块的 Lock 对象能够保证数据的正确性。
比如,使用多线程将抓取数据写入磁盘文件,此时,就要对执行写入操作的线程加锁,这样才能够避免写入的数据被覆盖。当线程执行完写操作后会主动释放锁,继续让其他线程去获取锁,周而复始,直到所有写操作执行完毕。具体方法如下所示:
from threading import Lock
lock = Lock()
# 获取锁
lock.acquire()
wirter.writerows("线程锁问题解决")
# 释放锁
lock.release()
Queue队列模型
对于 Python 多线程而言,由于 GIL 全局解释器锁的存在,同一时刻只允许一个线程占据解释器执行程序,当此线程遇到 IO 操作时就会主动让出解释器,让其他处于等待状态的线程去获取解释器来执行程序,而该线程则回到等待状态,这主要是通过线程的调度机制实现的。由于上述原因,我们需要构建一个多线程共享数据的模型,让所有线程都到该模型中获取数据。queue(队列,先进先出) 模块提供了创建共享数据的队列模型。比如,把所有待爬取的 URL 地址放入队列中,每个线程都到这个队列中去提取 URL。queue 模块的具体使用方法如下:
# 导入模块
from queue import Queue
q = Queue() #创界队列对象
q.put(url) 向队列中添加爬取一个url链接
q.get() # 获取一个url,当队列为空时,阻塞
q.empty() # 判断队列是否为空,True/False
多线程爬虫案例
下面通过多线程方法抓取小米应用商店(https://app.m网站站点" rel="nofollow" />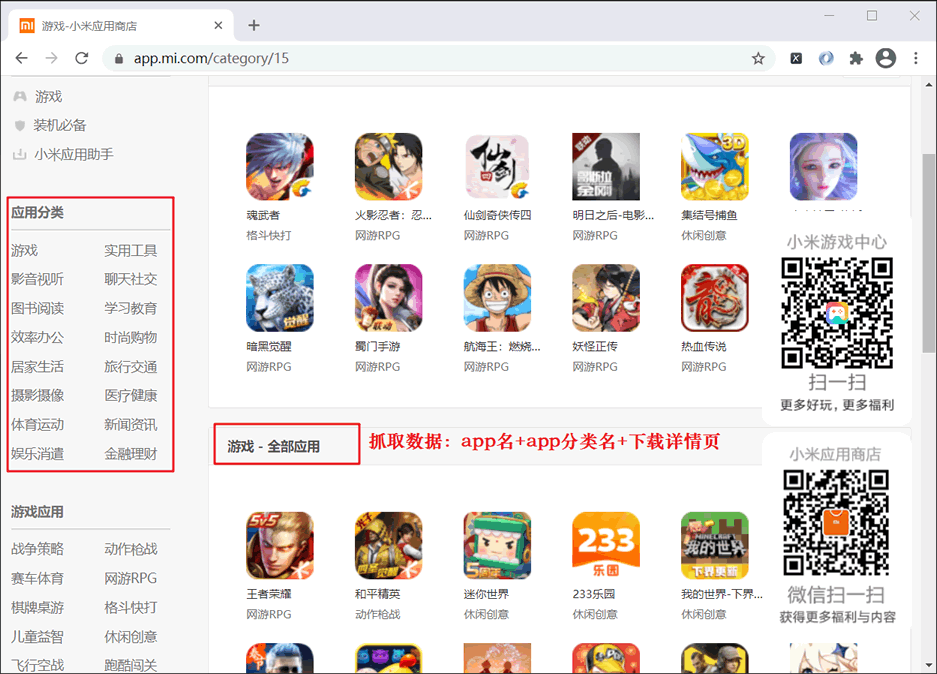
图1:小米应用商城
三国杀,棋牌桌游,http://app.m网站站点" rel="nofollow" />
https://app.m网站站点" rel="nofollow" />
<ul class="category-list">
<li><a class="current" href="/category/15">游戏</a></li>
<li><a href="/category/5">实用工具</a></li>
<li><a href="/category/27">影音视听</a></li>
<li><a href="/category/2">聊天社交</a></li>
<li><a href="/category/7">图书阅读</a></li>
<li><a href="/category/12">学习教育</a></li>
<li><a href="/category/10">效率办公</a></li>
<li><a href="/category/9">时尚购物</a></li>
<li><a href="/category/4">居家生活</a></li>
<li><a href="/category/3">旅行交通</a></li>
<li><a href="/category/6">摄影摄像</a></li>
<li><a href="/category/14">医疗健康</a></li>
<li><a href="/category/8">体育运动</a></li>
<li><a href="/category/11">新闻资讯</a></li>
<li><a href="/category/13">娱乐消遣</a></li>
<li><a href="/category/1">金融理财</a></li>
</ul>
因此,可以使用 Xpath 表达式匹配 href 属性,从而提取类别 ID 以及类别名称,表达式如下:
点击开发者工具的 response 选项卡,查看响应数据,如下所示:基准表达式:xpath_bds = '//ul[@class="category-list"]/li'
提取 id 表达式:typ_id = li.xpath('./a/@href')[0].split('/')[-1]
类型名称:typ_name = li.xpath('./a/text()')[0]
{
count: 2000,
data: [
{
appId: 1348407,
displayName: "天气暖暖-关心Ta从关心天气开始",
icon: "http://file.market.xiaom网站站点" rel="nofollow" />
pages = int(count) // 30 + 1
下载详情页的地址是使用 packageName 拼接而成,如下所示:
link = 'http://app.m网站站点" rel="nofollow" />
# -*- coding:utf8 -*-
import requests
from threading import Thread
from queue import Queue
import time
from fake_useragent import UserAgent
from lxml import etree
import csv
from threading import Lock
import json
class XiaomiSpider(object):
def __init__(self):
self.url = 'http://app.m网站站点" rel="nofollow" />
在我们之间-单机版,休闲创意,http://app.m网站站点" rel="nofollow" />
- 随机文章
- 核心危机(核心危机魔石合成攻略)
- 风儿(风儿轻轻的吹)
- 饿了么红包怎么用(饿了么红包怎么用微信支付)
- 儿童教育文章(儿童教育)
- 光遇花手先祖位置(安卓光遇手花先祖)
- 广州4a广告公司(广州4a广告公司创意总监年薪)
- 兵马俑(兵马俑介绍和历史背景)
- 陈武简历
- 帆船比赛(帆船比赛视频)
- 海猫鸣泣之时游戏(海猫鸣泣之时游戏在哪玩)
- 韩国媳妇和小雪(韩国媳妇和小雪的父亲工资是多少)
- 儋州市第二中学(儋州市第二中学录取分数线)
- 鬼泣5攻略(鬼泣5攻略第三关怎么跳)
- 和柳亚子(和柳亚子先生于田)
- 冰客(冰客果汁)
- yy魔兽(yy魔兽世界)
- 国外成人游戏(国外成人游戏注册需要visa信用卡)
- 充值卡代理(充值卡代理加盟)
- 郭妮小说(恶魔的法则郭妮小说)
- 东天目山(东天目山景区)
- 杭同(杭同培训中心怎么样)
- 蝙蝠给人类的一封信(蝙蝠给人类的一封信)
- 大松电饭煲(美的大松电饭煲)
- 服饰加盟(服饰加盟店招商)
- 疯狂填字(疯狂填字5)
- 点对点短信息(点对点短信息费是什么意思)
- 观音普门品(观音普门品念诵全文)
- 广州晓港公园(广州晓港公园正门图片)
- 钢筋等级符号(钢筋等级符号电脑怎么输入)
- 常州天宁寺(常州天宁寺求什么灵验)