Python爬虫实现Cookie模拟登录
Cookie 是一个记录了用户登录状态以及用户属性的加密字符串。当你次登陆网站时,服务端会在返回的 Response Headers 中添加 Cookie, 浏览器接收到响应信息后,会将 Cookie 保存浏览器本地存储中,当你再次向该网站发送请求时,请求头中就会携带 Cookie,这样服务器通过读取 Cookie 就能识别登陆用户了。
提示:我们所熟知的“记住密码”功能,以及“老用户登陆”欢迎语,这些都是通过 Cookie 实现的。
下面介绍如何实现 Cookie 模拟登录,本节以模拟登录人人网(http://life.renre网站站点" rel="nofollow" /> 图1:人人网主界面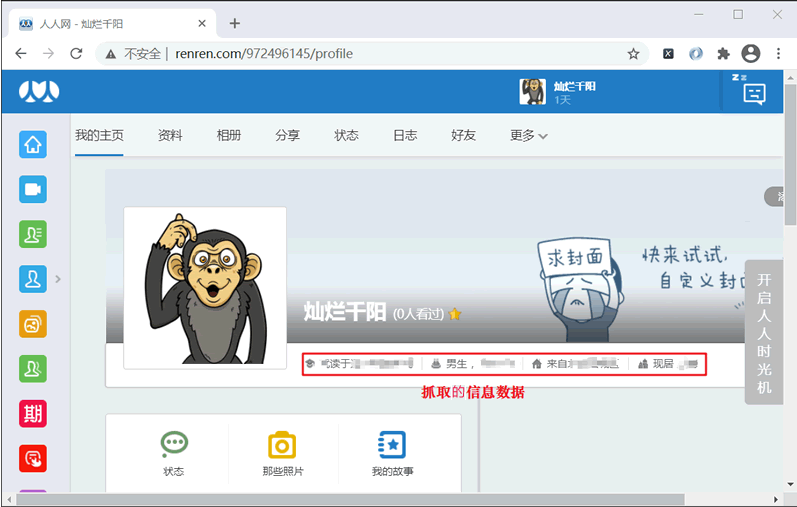
然后使用 F12 打开调试工具,刷新页面来抓取登录时的数据包(包名:timeline...开头), 并在 Headers 选项中找到请求头中的 Cookie 信息,将 Cookie 值拷贝下来,以备后续使用。如下所示:
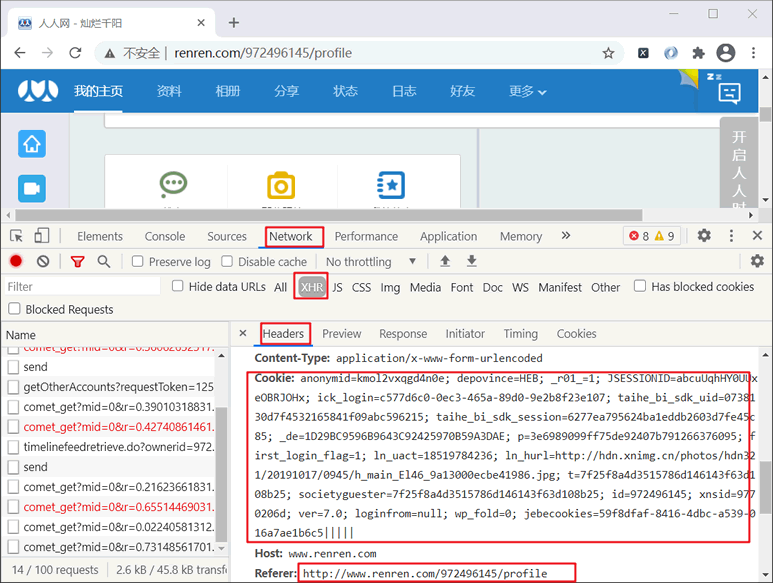
图2:浏览Headers信息
分析网页结构
确定了 Cookie 信息后,接下来分析页面元素结构。通过调试工具审查如图 1 所示的个人信息栏,其元素结构如下:
<div id="operate_area" class="clearfix">
<div class="tl-information">
<ul>
<li class="school"><span>就读于电子科技大学</span></li>
<li class="birthday">
<span>男生</span>
<span>,7月7日</span>
</li>
<li class="hometown">来自北京西城区</li>
<li class="address">现居 北京</li>
</ul>
...
</div>
</div>
由此可知其 Xpath 表达式为:
r_school = parse_html.xpath('//*[@id="operate_area"]/div[1]/ul/li[1]/span/text()'
r_birthday = parse_html.xpath('//li[@class="birthday"]/span/text()')
home_info=parse_html.xpath('//*[@id="operate_area"]/div[1]/ul/li/text()')
编写完整程序
完成程序如下所示:import requests
from lxml import etree
class RenrenLogin(object):
def __init__(self):
# 个人主页的url地址
self.url = 'http://www.renre网站站点" rel="nofollow" />
['就读于电子科技大学']
['男生', ',7月7日']
{'hometown': '来自 北京 西城区', 'address': '现居 上海'}